深入 Hadoop 大數據分析:初探網絡環境與設定
上回介紹了 Hadoop 每個不同部份所負責的功能後,那麼接下來我們將會開始帶大家探討一下當中的網絡環境與設定。
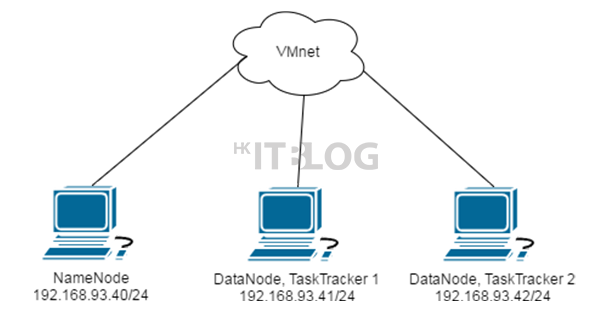
今次主要以 VMware Workstation 12.1.0 安裝和設定 Hadoop 叢集。在如圖 1 所示網絡設定為 NAT,全部虛擬機都連接 VMware 的內部網絡,各虛擬機都必須使用固定 IP 地址,以防止 IP 地址轉變令 Hadoop 叢集連接不到 NameNode。至於操作系統方面,本次將會使用 CentOS 7 Minimal 版本。原因是 Minimal 是最純正的 CentOS 7 版本,其中只包含 CentOS 7 的核心套件,使用者可根據自身需求安裝對應的軟體包,減少軟體間發生不兼容的情況,因此容量是最小的,系統運行時所佔的 RAM 也是最小。
CentOS 對比起另一 Linux 發行版—- Ubuntu 較小出現因為帳號權限問題所發生的錯誤。為了更清楚顯示 Hadoop 的安裝和設定過程,今次會使用三台虛擬機,分別為一台 NameNode (Master Server) 和兩台 DataNode, TaskTracker (Slave Server),其他硬件設定可查看以下表格:
|
NameNode |
DataNode, TaskTracker 1 |
DataNode, TaskTracker 2 |
| 系統 |
CentOS 7 Minimal |
CentOS 7 Minimal |
CentOS 7 Minimal |
| 主機名稱 |
Master |
Slave1 |
Slave2 |
| IP |
192.168.93.40/24 |
192.168.93.41/24 |
192.168.93.42/24 |
| vCPU |
1 Core |
1 Core |
1 Core |
| vRAM |
2 GB |
2 GB |
2 GB |
| 硬盤 |
20 GB |
20 GB |
20 GB |
CentOS 7 Minimal 安裝小提示
如下圖 2 所示,在 VMware 安裝 CentOS 7 的時候,KDUMP 若為自動開始有機會出錯,建議手動開啟。繼續如下圖 3 所示,為加快其後 Hadoop 設定過程,使用者可以在安裝介面 NETWORK&HOSTNAME 一欄中預先設定主機名稱,當然也可以在完成安裝後修改 /etc/hostname。
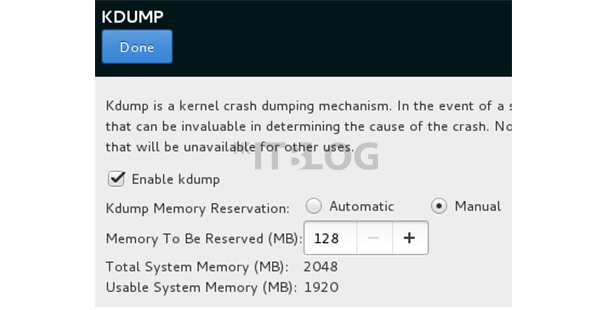
圖 2 手動開啟 KDUMP

圖 3 預先設定主機名稱
待續…
以上資訊由www.hkitblog.com提供
Categories: 市場快訊 Tags: DataNode, Hadoop, Hadoop 教學, HDFS, JobTracker, MapReduce, MapReduce 軟體架構, NameNode, TaskTracker, 大數據分析, 軟體架構
預測未來、把握機遇:2017 存儲及數據趨勢展望 – HKITBLOG
預測未來、把握機遇:2017 存儲及數據趨勢展望

又來到年尾了,在 2016 年大家除了應對不斷出現的網絡安全威脅之外,對於數據存儲方面的重視程度亦有所提升!其中一個十分主要的原因是「萬物互聯」;互聯網已成為日常工作、生活不可或缺的一部份,而每一個在網絡上的動作都會衍生出全新的數據,久而久之數據量會十分巨大,因此針對存儲及數據方面的趨勢預測亦是繼網絡安全趨勢後,另一個最備受關注的領域。為此我們在今次的文章之中亦將會與大家分享一下對來年在存儲以及大數據方面的一些看法。
1. 雲端到雲端的備份
現時很多企業都開始嘗試把大量數據備份到雲端,儘管這些雲端備份本身由十分大型的 IT 服務供應商經營,然而作為企業的 IT 主管仍無法放心下來,於是雲端至雲端的備份服務將應運而生!在 2017 年我們將會看到更多主打雲端到雲端的備份方案,通過這些方案讓雲端之間均可再進行雙重備份,務求令數據得到最全面的保護。
2. 發掘暗數據(Dark Data)的價值
對於那些正在使用大數據分析的企業來說,要如何找出暗數據,並從中獲得價值相信絕對是 2017 年的一大目標。所謂的暗數據就是指那些未被發現或無法得知如何使用的數據,一般來說這些數據可能包含一些人類不明白的 Log、來自社交媒體的非結構化數據等;在 2017 年我們將會看到企業願意花費更多用來研究暗數據的採用及分析工作,從而更快人一步洞悉暗數據價值。
3. 小型存儲品牌/服務供應商冒起
提到存儲,企業 IT 管理員第一時間會想到的就是那些傳統存儲大品牌,不過這些品牌將會於 2017 年感受到前所未有的挑戰。儘管由知名傳統品牌所提供的存儲方案的確能滿足到企業所需,然而價格卻不菲!
而那些以往只提供中小微企存儲系統的品牌,經過多年發展後亦推出了企業級數的存儲陣列,這些一直不起眼的存儲廠商,她們擁有多年的生產存儲設備經驗,再加上很多品牌都是陪伴著企業成長的,很多中小微企從第一天都在使用的 NAS 品牌,到現時已擁有企業級的全快閃存儲陣列;而這些當年的微企到現在亦已成長為一家大型企業,這時候選用沿用多年的品牌亦十分正常;再加上價格上對比傳統的存儲品牌一定有絕對的優勢,這些品牌已在不知不覺間蠶食了大型存儲品牌的生意。在 2017 年這趨勢將會繼續,而大型的傳統存儲品牌亦會開始發現這情況。
4. Hadoop 相關方案愈來愈多
Hadoop 是一套開源的大數據方案,然而部署上並不簡單,不過很多大型的 IT 品牌如 Google 等都在使用,驅使愈來愈多企業願意跟隨!在這種情況之下,2017 年我們將會看到更多圍繞 Hadoop 的大數據方案。透過這些由第三方開發,針對 Hadoop 的方案,企業將可更容易採用到 Hadoop,從而加快大數據的分析,並從中作出最佳的決策。
總結
存儲、大數據以及網絡保安相關方案將會主導未來的 IT 行業發展,作為 IT 管理員必須針對這三方面做好準備,例如多作進修學習新知識,以便有充足的能力完成計劃及部署相關工作,否則被淘汰將會是遲早發生的事情。
以上資訊由www.hkitblog.com提供
Categories: 市場快訊 Tags: Dark Data, Flash, Flash Array, Flash 儲存陣列, Flash 存儲陣列, Hadoop, NAS, 儲存, 儲存系統, 大數據, 存儲, 存儲系統, 數據, 數據管理, 暗數據, 雲端備份

目前,大數據仍然不算普及,但並不代表大數據是沒有意義的技術,其價值及分析結果已經令很多企業家垂青。企業都在開始嘗試利用大數據來增強自己的企業業務競爭力,但是對於大數據分析行業來說,這技術仍然處於快速成長的初期,這領域仍有很多未定型的技術範疇,潛能可謂無法預視。現在企業最想知道的,應該是緊貼發展趨勢吧。以下有五項技術趨勢,CIO會更了解如何時署合適自身業務的大數據方案:
1.基於雲的大數據分析
Hadoop是用於處理大型資料集的一個框架和一組工具,這個最初設計在物理機上工作,但是目前這種現象已經改變,越來越多的基於雲的數據處理技術出現,例如Amazon AWS的Elastic MapReduce (EMR),Google BigQuery中的資料分析服務,IBM的Bluemix雲平台等等,這些都是基於雲的大數據分析平台。
就目前而言,大數據的分析工作正開始向公用雲遷移,因為大數據分析需要一個安全、穩定、可靠的審計環境。目前已經有很多公司開始跟雲服務公司合作,希望得到一個能夠橫跨多個部門的雲平台來支援公司的業務資料分析。隨著雲平台成本的降低,這個趨勢將越發明顯,部署大數據已經不再是大企業專利。
2.Hadoop:新的企業資料作業系統
Hadoop分散式的分析框架,如今正在演變成分散式資源管理器,它可能將是資料分析的一個通用作業系統。有了這些系統,你可以將不同的資料操作和分析操作插入到Hadoop分散式存儲系統中來執行。由於SQL、MapReduce,在記憶體中,串流處理、圖形分析和其他類型的工作負載都能夠在Hadoop上有足夠的性能運行,越來越多的企業將會使用的Hadoop作為企業資料中心。
3.更多的預測分析
隨著大數據的發展,分析師不僅會累積更多的數據一起工作,而且還將處理大量許多屬性的工具。但是隨著大數據行業的發展,針對舊資料的分析更多的是為了提供預測的功能,畢竟人們更希望利用已有的資料來對未來預測有利的用途。
4.更多,更好的NoSQL
替代傳統的基於SQL的Relational Database的產品被稱為NoSQL,如今開始在特定種類的分析應用程式中普及。以這一增長趨勢估計,預計未來將有15至20個開源的NoSQL資料庫共同存在,他們各自有專長,這些資料庫會得到快速的發展。
5.在記憶體分析
使用記憶體來加快分析處理的技術如今越來越受歡迎,實時分析是很多企業使用者都喜歡的產品,目前很多基於記憶體的分析管理工具以及出現,其中以亞馬遜的HANA一體機尤為明顯。
總結:資料分析是一個熱門行業,未來有很大發展的空間,所以目前很多廠商都針對大數據分析領域推出產品,但是對於企業使用者來說,在選擇產品的時候要注意,由於目前資料分析尚沒有到達成熟的市場時期,所以市場上的分析工具參差不齊,在選擇產品的時候還是要選擇知名品牌為好。
以上資訊由www.hkitblog.com提供

透過分析大數據,企業將能洞悉未來的趨勢,從而令企業快人一步,把握即將到來的商業機會。前面這句說話,很多推出大數據方案的廠商都曾經說過,而很多企業想必也了解到大數據的價值;不過要企業部署大數據相關方案並非易事,除了大數據方案普遍昂貴之外,儲存架構是否足以應付數據增長速度、存儲媒介的效能是否能提供流暢的速度以應付分析方案的要求等,都是企業立即需要面對的問題。
其實分析方案的速度與基建的「質素」有絕對的關係,所以儘管廠商聲稱其方案提供極高速度也好,都要基建的配合才可。今天 Splunk 亦推出聲稱擁有極高速的大數據分析方案,名為 Splunk Analytics for Hadoop beta 版。Hunk(目前為 beta 版) 為 Splunk 軟體產品,具備 Hadoop 資料探索、分析、圖像化功能,並以 Splunk 的分析技術為基礎。官方稱透過方案將能提升與 Hadoop 資料互動及分析的速度,毋需設計程式、斥資整合或被迫搬移資料。

無需程式設計或整合
坊間針對大數據的分析方案,很多時都需要針對數據進行相應的設定及調整,這個過程往往需花上一些時間;但今次介紹的 Splunk 則可大大省去這些動作。首先它本身提供虛擬索引功能,這種虛擬索引技術可讓用戶使用所有 Splunk 技術,包括運用 Splunk Search Processing Language、互動式探索、分析與圖像化資料,當中最為重要的就是可不受儲存位置限制,而是如同存放在 Splunk 索引之中。Hunk 即是以此基礎技術為根本的方案。
而 Hunk 本身在設計上已支援用於互動式探索大型多元資料庫,用戶可在無需事先瞭解資料內容的情況下直接將 Hunk 設定於 Hadoop 群集;配合上方案提供的深層分析,讓你可實時從龐大資料中進行搜索及分析;另外,為解決可能發生的種種異常情況,方案亦同時提供自動偵測功能,此功能主要能偵測各項模式與異常狀態,也可能從資料中發掘趨勢,並找出值得注意的規則及模式。
除了擁有強大的搜索功能外,其分析後所產生的報表亦符合「容易明白」的原則,使用者將能夠製作精緻圖表,讓資料更具意義,並可分享予手提電腦、平板,或是其他行動裝置的用戶,讓管理層亦可直接查看結果,減輕 IT 部門的工作量;同時企業亦可因本身使用的習慣而自定報表,包括能將各種圖表結合一起、觀點與數據的設定等等;更甚者亦可針對不同人員製作控制頁面,最終用戶只需透過筆記型電腦、平板電腦或其他行動裝置即可瀏覽與編輯,實行將複雜的大數據分析工作變得更為簡單。
以上資訊由www.hkitblog.com提供
Categories: 市場快訊 Tags: Big Data, Big Data Software, Hadoop, Hunk, Splunk, Splunk Analytics for Hadoop beta, Splunk Search Processing Language, 互動式分析, 互動式圖像化, 互動式探索, 儲存架構, 分析大數據, 分析大數據方案, 分析大數據軟件, 分析方案, 大數據分析, 大數據分析方案, 大數據分析軟件, 大數據方案, 存儲媒介, 數據分析, 數據增長, 異常狀態, 自動偵測, 虛擬索引, 資料分析, 資料圖像化, 資料探索
