深入Hadoop大數據分析:初探網絡環境與設定
February 25th, 2017
No comments
深入 Hadoop 大數據分析:初探網絡環境與設定
上回介紹了 Hadoop 每個不同部份所負責的功能後,那麼接下來我們將會開始帶大家探討一下當中的網絡環境與設定。
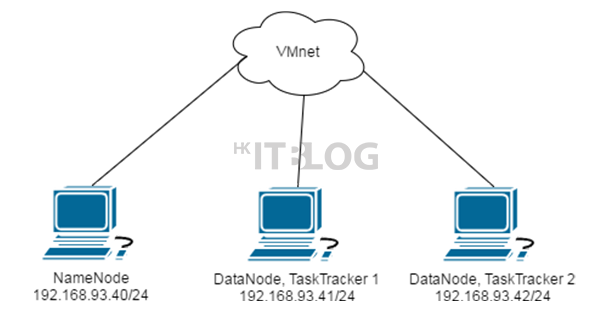
今次主要以 VMware Workstation 12.1.0 安裝和設定 Hadoop 叢集。在如圖 1 所示網絡設定為 NAT,全部虛擬機都連接 VMware 的內部網絡,各虛擬機都必須使用固定 IP 地址,以防止 IP 地址轉變令 Hadoop 叢集連接不到 NameNode。至於操作系統方面,本次將會使用 CentOS 7 Minimal 版本。原因是 Minimal 是最純正的 CentOS 7 版本,其中只包含 CentOS 7 的核心套件,使用者可根據自身需求安裝對應的軟體包,減少軟體間發生不兼容的情況,因此容量是最小的,系統運行時所佔的 RAM 也是最小。
CentOS 對比起另一 Linux 發行版—- Ubuntu 較小出現因為帳號權限問題所發生的錯誤。為了更清楚顯示 Hadoop 的安裝和設定過程,今次會使用三台虛擬機,分別為一台 NameNode (Master Server) 和兩台 DataNode, TaskTracker (Slave Server),其他硬件設定可查看以下表格:
| NameNode | DataNode, TaskTracker 1 | DataNode, TaskTracker 2 | |
| 系統 | CentOS 7 Minimal | CentOS 7 Minimal | CentOS 7 Minimal |
| 主機名稱 | Master | Slave1 | Slave2 |
| IP | 192.168.93.40/24 | 192.168.93.41/24 | 192.168.93.42/24 |
| vCPU | 1 Core | 1 Core | 1 Core |
| vRAM | 2 GB | 2 GB | 2 GB |
| 硬盤 | 20 GB | 20 GB | 20 GB |
CentOS 7 Minimal 安裝小提示
如下圖 2 所示,在 VMware 安裝 CentOS 7 的時候,KDUMP 若為自動開始有機會出錯,建議手動開啟。繼續如下圖 3 所示,為加快其後 Hadoop 設定過程,使用者可以在安裝介面 NETWORK&HOSTNAME 一欄中預先設定主機名稱,當然也可以在完成安裝後修改 /etc/hostname。
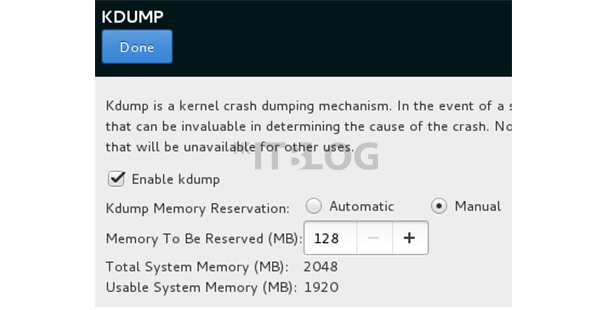
圖 2 手動開啟 KDUMP

圖 3 預先設定主機名稱
待續…
以上資訊由www.hkitblog.com提供
Categories: 市場快訊 DataNode, Hadoop, Hadoop 教學, HDFS, JobTracker, MapReduce, MapReduce 軟體架構, NameNode, TaskTracker, 大數據分析, 軟體架構
